
前回の投稿で、Notion関数を使った記事チェックツールのベースを作りました。既に実作業でも使っていて、結構いい感じでございます。
が……。
クライアントのレギュレーションに合わせて調整していたところ、うまくいかない操作がありました。
それが正規表現+containsです。使えないなら使わないし、別の方法を考えねば……。
ってことでreplaceAllの万能感が半端ないっていうお話と、私(@saosaoyamayama)が実際にやったことを記録しておきます。
Contents
NGワード判定にcontainsが効かない
記事内で使ってはいけない単語が含まれているか否か。このジャッジで使える関数が[contains]です。
前回のエントリーでは[contains]を使って正確な判定ができていました。
でも前回検出していたのは「単語」「HTMLタグ」だったんですよね。正規表現で引っかかったものを検出するっていうのは、やっていませんでした。

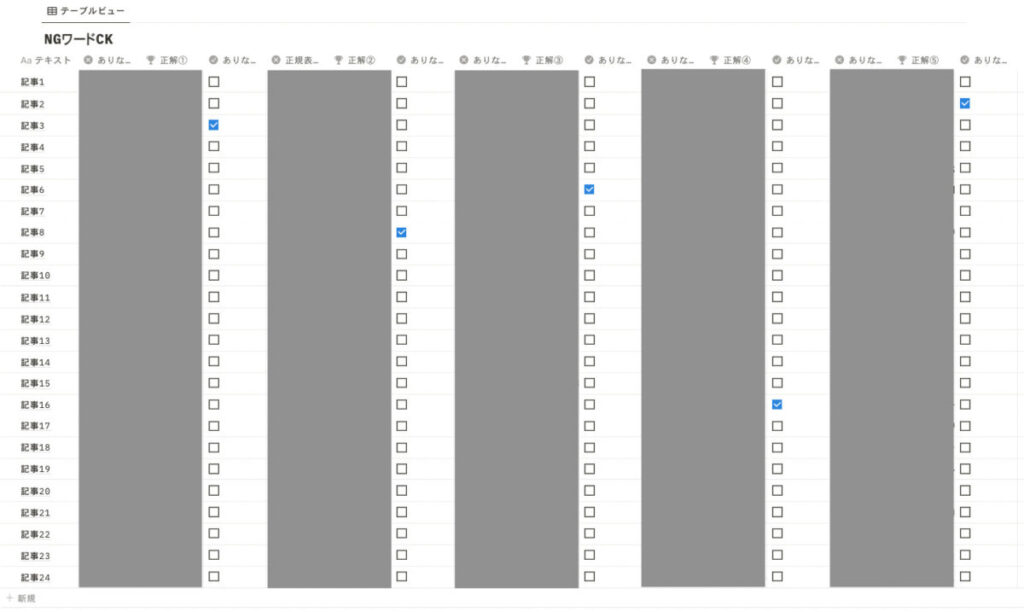
テキスト内に<h2>見出しが入っていたら[Σcontains単体]にチェックが付くようにしました。関数は以下のとおりです。
contains(prop("名前"), prop("NGワード"))最初の<h2>はうまく検出できていますね。関数は正しく動いているようです。
正規表現として設定した「<\/?h2>」は、H2タグを数えるときに活躍した実績アリの正規表現です。
この正規表現を使って[contains]を適用してみると……。動かない! 動かない!
正規表現は[replaceAll]では動くのに、[contains]では動かないのか。
なお、直書き(関数内にproperty記述せず書き込む)でもうまくいきませんでした。
何かミスっているのかな……ひとまず回避策を考えることにします。
回避策はreplaceAllとcontainsの合わせ技
結局今回も泥臭い感じでやることにしました。
もしかして[replaceAll]はパーフェクトオールラウンダー※では?
※ワールドトリガー・木崎レイジ
やること
- 記事内であまり使わない記号を1つチョイス(今回は★)
- 念のため記事内の★を検索して[replaceAll]で削除
- 記事内にNGワードがあったら[replaceAll]で★に置換
- ★があるかないか[contains]で判定
泥臭WAYですね。実際にやってみますか。
記事内の★を念のため削除

★なんて使わねえだろと思っていましたが、初っ端から★を使った記事にぶつかってびっくりしました。
そのため「元記事に★があったら削除」という関数を挟むことにします。
replaceAll(prop("★あり記事"), "★", "")「つのだ☆ひろ」は★じゃないので削除できないですね。あとダイヤモンド☆ユカイも(そもそも星じゃない)。
NGワードマッチングと判定

【contains単体】
=contains(prop("名前"), prop("NGワード"))
【replaceAll+contains】
・Σ★に置換
=replaceAll(prop("名前"), prop("NGワード"), "★")
・ΣreplaceAll+contains
=contains(prop("★に置換"), "★")- Σcontains単体:containsだけでNGワードを検出
- ΣreplaceAll+contains:NGワードを「★」に置換してから「★」を検出
どちらも[NGワード]列のワードを検出しているのに、結果が異なります。正しいのは[replaceAll+contains]です。
できないものは仕方がない。ここで足踏みしているより、未来に向かって小さな一歩を踏み出すべきではありませんか!
replaceAll+containsを使う利点

関数を2段構成で使うのはとても泥臭くて面倒に感じるかもしれません。でもツール作成に限っていえば、関数をセットするのは1回だけ。
それにNotionはプロパティ(列)内に1つ関数を設定すると縦方向に関数が自動適用されるので、大変ではありません。
「チェックツール」っていう前提なら、泥臭い関数にもメリットがあります。
- [replaceAll+contains]は正規表現でもそうじゃなくてもジャッジできる
- 類似NGワードを正規表現で1つにまとめられる(これは正規表現のメリットか)
正規表現もそれ以外も検出できるしカウントにも応用できる
「あれぇぇぇ、正規表現で[contains]が使えん……」と気付いて、すぐに「★置換検出列」を作りました。でも「★置換検出列」はすぐに足りなくなりました。
はっ、もしかして全部「★置換検出」にしちゃえばよいのでは……!?
[replaceAll+contains]は単語・正規表現問わず検出できるので、最初からコレでツール作っておけばOK。
しかも「★」に置換しているので、置換後の文章を見れば「ここが引っかかっていますよ〜」っていうのがすぐにわかります。
正規表現で複数ワードをまとめてジャッジできる
これは正規表現のメリットなんですけどね。
「NGワード」といっても単語そのものがNGっていうパターンだけじゃありません。漢字の閉じ開きとか送り仮名とか、クライアントによっていろいろあります。
- NG:目一杯・目いっぱい
- OK:めいっぱい
こんな感じのルールがあったとします。
もし正規表現を使わないなら「目一杯」「目いっぱい」をそれぞれジャッジする必要があります。2項目分(4〜6列)を使うんですよね。項目が少ないならこれでもいい。
でも、とあるクライアントは検出語120項目なので(別の記事で……)少しでも減らしたいんです。
「目(一杯|いっぱい)」「目一杯|目いっぱい」などの正規表現を使えば、1項目分(2〜3列)で2項目分検出できます。
検出したあと「どっちだ、引っかかったのはどっちだ」って調べる必要はありますけど、それは「★」がどこにあるかを見ればいい話。
滅多に出てこないNGワードはまとめて正規表現化して「or」検索させればいいかなと思っています。超絶イレギュラーのNGワードは素読みの段階で気付いて修正することがほとんどですけどね。
正規表現が使えると、Notionの記事チェックツールが多少スリム化できると思っています。
大量のNGワードチェックで問題発生!

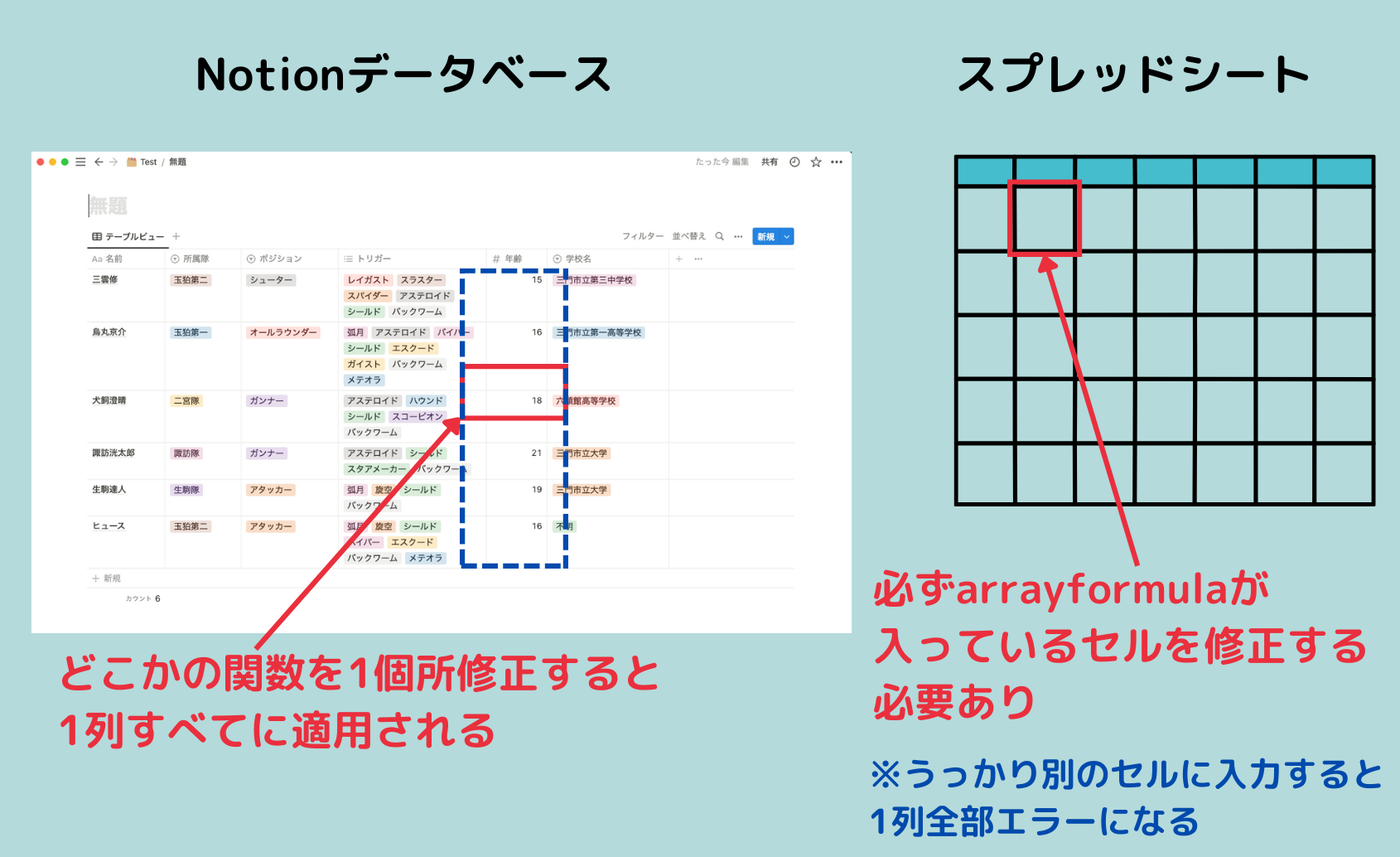
大量のNGワードチェックでは、データベースを横に広げるか縦に伸ばすか問題が発生します。
横に広げると横スクロールが必要なので縦に伸ばしたい。縦に伸ばすとそれはそれで問題が……。
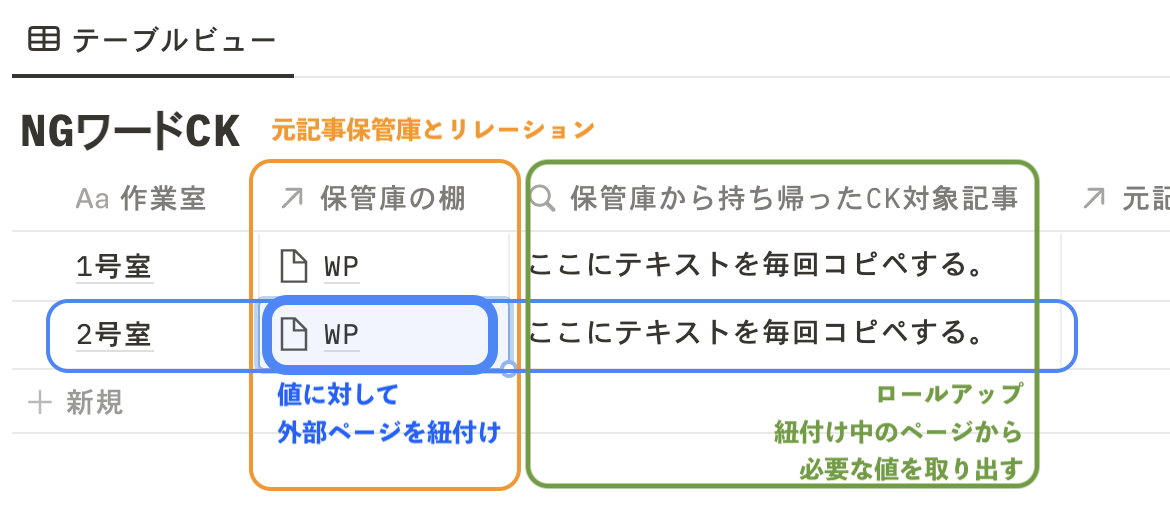
ということで次回は「大量コピペを回避するためにリレーションとロールアップという技を覚えた」話です。


ピンバック: Notionのリレーション・ロールアップでコピペの手間削減|NGワード検出ツール作成 – 自分でやります、はい。
ピンバック: Notion関数で記事チェックツール作り|スプレッドシートにどこまで近付けるかチャレンジ – 自分でやります、はい。